Значительную помощь в проведении лингвистических исследований оказывают программные средства, которые позволяют в автоматическом режиме находить нужные языковые единицы и составлять их конкорданс.
Конкорданс, в общем случае понимаемый как представление опорной языковой единицы во множестве всех ее контекстных окружений, востребован не только как лексикографический формат, но и как инструмент лингводидактики, используемый для отбора и оценки лингводидактического материала, а также как исследовательский инструмент, применимый для определения семантических, грамматических, сочетаемостных характеристик опорной языковой единицы [1, с. 108].
Результаты работ в области компьютерной лингвистики дали новые предпосылки для исследований морфологических, семантических, синтаксических и словообразовательных связей в естественном языке. Однако не многие программные средства могут использоваться для поиска единиц низших уровней, например, префиксоидов. В трактовке префиксоидов и их особенностей следуем Б. В. Орехову: «префиксоиды — пограничное явление в словообразовании. С одной стороны, они участвуют в создании сложных слов, выступая в позиции приставки. С другой, происходя от самостоятельных слов, они не утрачивают лексического значения, и в этом больше похожи на корень, чем на приставку» [2, с. 281].
В данной статье опишем такие корпусные ресурсы, которые предоставляют возможность получения конкорданса слов с префиксоидами по русскоязычным текстам: Национальный корпус русского языка (далее – НКРЯ) [3], WebCorp [4], Intellitext [5]. Все перечисленные программные средства свободно доступны в онлайн-режиме.
- Национальный корпус русского языка
Национальный корпус русского языка – большой, сбалансированный по составу электронный
корпус текстов; ядро НКРЯ составляют русскоязычные тексты, однако входящий в НКРЯ параллельный корпус содержит «мультиязычную» часть (тексты переводов с русского и на русский).
Словообразовательная разметка в НКРЯ реализована в двух вариантах, первый из которых – реализация в составе семантической разметки; определение параметров словообразовательной разметки в этом случае производится выбором в форме «Лексико-грамматический поиск» окна «Семантические признаки» и далее – выбором параметров группы «Словообразование», доступных в данном окне. В этом виде разметки набор словообразовательных параметров соответствует следующим типам характеристик: морфо-семантические словообразовательные признаки; разряд производящего слова; лексико-семантический (таксономический) тип производящего слова; морфологический тип словообразования [6]. Данный вариант словообразовательной разметки доступен только в семантически размеченных корпусах НКРЯ: основном, газетном, параллельном, поэтическом, устном, акцентологическом, мультимедийном. Обращение к этому варианту словообразовательной разметки не позволяет искать слова с префиксоидами.
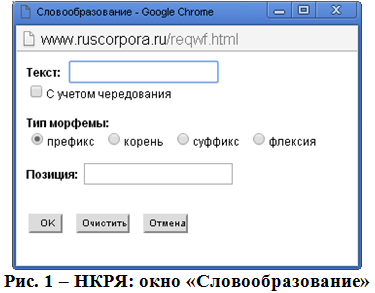
Еще один, второй, вариант словообразовательной разметки НКРЯ доступен только в основном корпусе НКРЯ. Определение параметров словообразовательной разметки в этом случае производится выбором в форме «Лексико-грамматический поиск» окна «Словообразование» и определения в нем типа и позиции морфемы (см. Рис.1).
При определении статуса префиксоидов разработчиками была выбрана следующая стратегия: «префиксоиды учтены при разметке, при этом префиксоиды следует разделить на префиксы и связанные корни … в зависимости от того, сохраняет ли та или иная единица возможность самостоятельного употребления не в составе сложного слова» [7]. К сожалению, на настоящий момент функция обработки этого, позволяющего находить слово с префиксоидами, варианта разметки нестабильна.
В НКРЯ наиболее простым и удачным способом поиска слов с префиксоидом является поиск по маске «*» со значением ‘0 и более символов’. Запрос вида «префиксоид* -префиксоид» вводится в поле «Слово» формы «Лексико-грамматический поиск». Компонент запроса «-префиксоид» вводится для того, чтобы исключить из выдачи «чистый» префиксоид; также можно исключать слова, где префиксоид выступает как корень. Например, на поиск по маске авиа* в выдачу, помимо слов с префиксоидом (авиамоторный, авиастроительный и т.п.), попадут слова, в которых авиа является корнем, а не префиксоидом (авиатор, авиация, авиационный) и слово авиа. Поэтому маска для создания конкорданса с префиксоидом авиа имеет вид:
авиа* -авиа —авиатор -авиация –авиационный (список исключаемых слов при необходимости можно расширить).
Первая страница выдачи по вышеприведенному запросу содержит конкордансные линии для следующих слов: авиабилет, авиабомба, авиагородок, авиадиспетчер, авиакомпания, авианосец, авиастроение, авиатехник.
Достоинством НКРЯ также можно считать возможность постобработки результатов средствами самого ресурса: получать график распределения по годам, статистику по метаатрибутам (тематике текстов, авторам, жанрам). Выдача может быть представлена в формате полного конкорданса (по умолчанию) и в формате KWIC. После сохранения выдачи в форматах Excel, OpenOffice Calc, XML возможна постобработка средствами сторонних программ.
WebCorp работает над выбранной информационно-поисковой системой, обрабатывая список возвращенный ею URL и извлекая из найденных страниц строки конкорданса по запросу.
Поиск слов с префиксоидами можно осуществлять по маске с использованием знака по маске «*» со значением ‘0 и более символов’. С помощью оператора | (или) можно осуществить одновременный поиск по нескольким словам. Квадратные скобки используются для группировки элементов запроса.
Опция «Word Filter» позволяет включать дополнительные слова, которые должны или не должны появляться в конкордансных линиях, извлекаемых по поисковому запросу.
В поле «Site» можно определить область поиска через набор доменных зон или фрагментов URL. Также можно указать домены, которые не должны быть включены в результаты поиска, написав их со знаком минус.
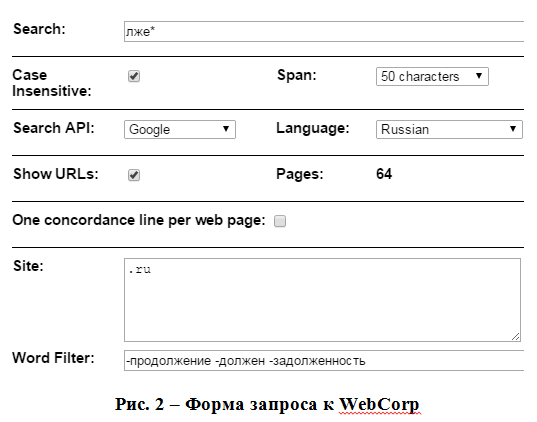
Приведем пример запроса к ресурсу (форму запроса см. на Рис. 2); поисковая строка: лже*, язык: русский, доменная зона: .ru, в фильтр слов со знаком минус включены слова продолжение, должен, задолженность (программа выдает список слов, которые содержат элемент лже). Синонимичный запрос: [ ]лже* (оператор группировки использован нестандартно: в квадратных скобках введен обязательный начальный пробел; ср., например запрос [лже|квази]нау[к|ч]*, где оператор группировки используется для ввода синонимичных префиксоидов и определения чередования к//ч).
Как и в НКРЯ, в WebCorp есть функции постобработки результатов. Когда поиск завершился, на странице результатов предоставляется возможность анализировать коллокации вашего поискового термина, то есть слова, которые чаще всего появляются в его окружении. Будет показана таблица частот для слов в четырех позициях слева и справа от поискового термина. Также возможна сортировка коллокатов по алфавиту и по дате. Имеется две возможности сортировки по дате:
- Можно выбрать период времени из выпадающего меню: в прошлом месяце, в течение последних 3-х месяцев, в течение последних 6 месяцев, и в прошлом году, более чем 1 год назад, более 2 лет назад, более 5 лет назад;
- выбрать «заданный диапазон» из выпадающего меню и ввести диапазон дат в текстовое поле: 4 цифры года, за которым следует дефис, а затем 2 цифры месяца, за которым следует дефис, затем 2 цифры дня (YYYY-MM-DD).
3. IntelliText
IntelliText имеет специальную функцию «Affixes», позволяющую осуществлять поиск префиксам либо суффиксам. Если необходимо найти префиксоид, то используется поиск по префиксам.
Стоит уточнить, что поиск введется не по настоящим префиксам, а по части, которая предваряет определенное слово.
Например: по запросу слов с префиксоидом земле в выдачу, помимо слов с префиксоидом, будут попадать слово землей (см. Рис. 3).
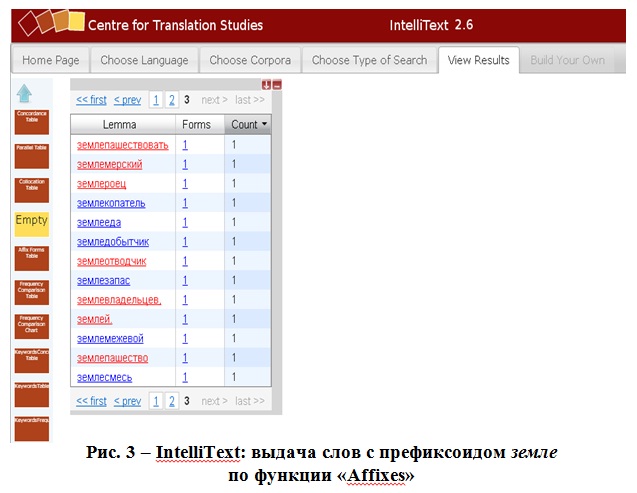
Выдача представлена в виде таблицы, где показаны: количество форм данного слова, лемма, а сами слова рассортированы по частоте употребления в корпусе. Возможности постобработки результатов достаточно широки. Результаты выдачи можно представить в формате KWIC. Для форм слова и его окружения даются пояснения, например: частота, часть речи, лемма и др.
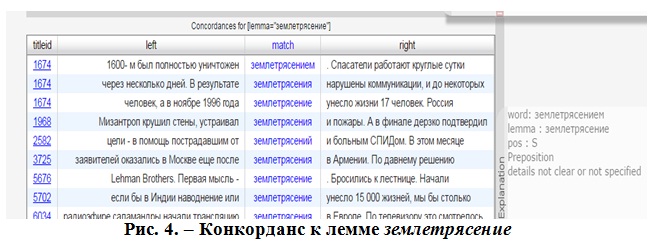
Пример конкорданса леммы землетрясение приведен на Рис. 4. При обращении к правой всплывающей панели можно получить дополнительную информацию о части речи, лемме не только поискового термина, но и слов, находящихся в его окружении.
На основе вышеизложенного можно сделать вывод, что рассмотренные программы пригодны для поиска слов с префиксоидами, но стоит заметить, что ни одна из них не способна дать результат без «шума», т.е. выдачу, в которой встречались бы лишь слова с префиксоидами. Однако данные программы значительно упрощают поиск таких слов и могут оказать существенную помощь в проведении лингвистических исследований.
Список использованных источников
-
Станкевич, А.Ю. Программные инструменты создания конкордансов для белорусскоязычных опорных единиц / А. Ю. Станкевич // Вестник МГЛУ. Сер. 1. Филология. – 2016. – № 1 (80) – С. 108–115.
-
Орехов Б. В. Суперминимум и нанодержава: префиксоиды в языке интернета // Современный русский язык в интернете. — М.: Языки славянской культуры, 2014. — С. 281–290.
-
Национальный корпус русского языка [Электронный ресурс] / Национальный корпус русского языка; Яндекс. – Режим доступа: http://www.ruscorpora.ru. – Дата доступа: 26.03.2016.
-
WebCorp [Electronic resource] / Research and Development Unit for English Studies, Birmingham City University. – Mode of access: http://www.webcorp.org.uk/live/. – Date of access: 27.03.2016.
-
IntelliText [Electronic resource] / University of Leeds: Centre for Translation Studies (CTS). – Mode of access: http://corpus.leeds.ac.uk/itweb/htdocs/Query.html. – Date of access: 27.03.2016.
-
О лексико-семантической информации в Корпусе [Электронный ресурс] / Национальный корпус русского языка; Яндекс. – Режим доступа: http://www.ruscorpora.ru/corpora-sem.html. – Дата доступа: 03.2016.
-
Тагабилева, М.Г. Словообразовательная разметка Национального Корпуса русского языка: задачи и методы [Электронный ресурс] / М. Г. Тагабилева, Ю. Н. Березуцкая. – Режим доступа: http://www.dialog-21.ru/digests/dialog2010/materials/pdf/73.pdf. – Дата доступа: 03.2016.