
Данная работа направлена на описание статистических приемов выявления коллокаций, а также на изучение природы коллокаций в текстах студенческих газет (на материале мини-корпуса учебных газет студентов специальности «Журналистика»).
М.В. Хохлова в работе «Исследование лексико-синтаксической сочетаемости в русском языке» отмечает, что в современной лингвистике важным источником и инструментом лингвистических исследований и решения прикладных задач стали корпусы текстов. «Статистический аппарат, применяемый в корпусах текстов, позволяет пользователям ранжировать результаты поиска по разным параметрам и задавать пороговые значения, что приводит к выдаче наиболее значимой информации» [1, с. 207]. Одним из востребованных программных фильтров для пользователя корпуса могут стать фильтры коллокаций, которые способны отбирать «значимые факты языка, относящиеся, в частности, к теоретическим и прикладным аспектам сочетаемости» [1, с. 207].
Таким образом, актуальность темы обусловлена тем, что получение новых данных о сочетаемости и разработка новых методов изучения коллокаций должны способствовать развитию исследований по лексикографии, а также исследований в области синтаксиса, семантики.
В корпусной лингвистикепод коллокацией обычно понимается «последовательность из двух или более слов, частотность совместного появления которых в тексте выше, чем ожидаемая вероятность их совместного появления» [2, с. 13].
По замечанию Е.В. Ягуновой, коллокации «достаточно часто выступают в качестве важной и частотной единицы словаря» [3, с. 27]. Как ядерные могут рассматриваться «коллокации, соответствующие неоднословным номинациям» [3, с. 27]. Коллокации занимают среднее звено на шкале «слово – коллокация – конструкция»; ядерные коллокации могут быть противопоставлены конструкциям «как парадигматические vs. синтагматические единицы; инвентарные vs. конструктивные единицы; единицы, принадлежащие лексикону vs. синтаксису; номинации vs. предикативные единицы» [3, с. 27].
За последние годы появилось большое число исследований и разработок, посвященных коллокациям, затрагивающих как теоретические аспекты статистического подхода к данному понятию, так и практические методы выявления коллокаций. Выявление коллокаций на базе статистических методов занимает ведущее место в практике прикладной лексикографии.
Для автоматического извлечения коллокаций из текста, производимого с опорой на статистические методы, используются различные меры ассоциативной связи, которые оценивают, является ли взаимное появление лексических единиц случайным, или оно статистически значимо. Но надо уточнить, что мера ассоциативной связи используется просто для ранжирования результатов, для решения задачи классификаций результата, для определения типичных структур коллокаций должны применяться другие методы.
Для измерения (то есть квантитативной оценки устойчивости) ассоциативной связи используются такие меры ассоциативной связи, как MI (MutualInformation), t-критерий Стьюдента, z-score и другие.
В нашей работе для отбора коллокаций мы обращались к критерию MI. Выбор критерия MI обусловлен тем, что он обычно дает наилучшие результаты при выделении устойчивых фразеологизированных словосочетаний (см., например: «…значение MI-score больше указывает на тематическое сходство между словами) [4].
МераMI,введеннаявработеK.W.Church, P.Hanks1990 (эти сведения даем по М.В. Хохловой [1]), сравнивает зависимыеконтекстно-связанныечастоты с независимыми, как если бы слова появлялись в тексте совершенно случайно. Значение MIвычисляется по формуле:
где n– ключевое слово, c– коллокат, f(n,c) – частота совместной встречаемости ключевого слова n и коллоката с;f(n),f(c) – абсолютные частоты ключевого слова nи коллоката cв корпусе (тексте);N– общее число словоупотреблений в корпусе (тексте).
Функция вычисления критерия связности обычно доступна в таких программных средствах анализа коллекций (корпусов) текстов, как корпус-менеджеры (AntConc, XAIRA, он-лайн корпус-менеджер от группы АОТ и др.).
В нашей работе для извлечения коллокатов использовалась разработанная А.Ю. Станкевич утилита расчета критериев связности, принцип работы которой описан в [5].
В качестве опорных слов для поиска коллокатов мы взяли список из 19 высокочастотных (но не служебных) слов, встречающихся во всех газетах мини-корпуса студенческих газет: Беларусь, день, студент, история, Гродно, город, женщина, мужчина, девушка, ночь, возможность, мир, век, история, жизнь, взгляд, человек, праздник, слово. Список был сформирован в автоматизированном режиме. Критерий связности рассчитывался отдельно для левого и для правого окружения опорного слова в окне размером 3 словоформы (при появлении знака препинания утилита сужает окно до предшествующего этому знаку символа). Словоформа интерпретировалась утилитой как ограниченный пробелами (на границах окна – пробелом и/или знаком препинания) набор символов латиницы, кириллицы, арабских цифр; точка в сокращении и дефис не считались границей словоформы [5, с. 163].
Исследование проводились на мини-корпусе текстов студенческих газет, созданных студентами специальности «Журналистика»; объем мини-корпуса: 42 662 словоформ, 82 854 словоупотреблений. Анализировались левые горизонты опорных слов.
Из полученного в автоматическом режиме списка коллокатов мы исключили единицы с MI< 1; результат обрабатывали по следующему алгоритму:
ШАГ-1. Из отобранных в автоматическом режиме левых горизонтов для опорных слов исключались, во-первых, незнаменательные слова, во-вторых, слова, синтаксически не связанные с опорным словом. В результате получим не просто список левых горизонтов, а список слов, синтаксически связанных с опорным (для удобства назовем его левым синтаксическим горизонтом).
ШАГ-2. В автоматическом режиме составили ЧС левых синтаксических горизонтов.
ШАГ-3. Неединичные коллокации в ручном режиме сортировались по функциональным группам.
С обращением к выбранной методике были выявлены следующие функциональные группы коллокаций:
- терминологические коллокации (например: всемирная история, областной город, магдебурское право);
- деривационные сочетания (например: житель Гродно, молодой человек, город Гродно);
- устойчивые глагольно-именные сочетания (например: задаться вопросом, сделать выговор);
- стандартные метафоры: (безжалостный мир, бурный восторг, вихрь жизни, водоворот жизни, неизгладимое впечатление);
- коллокации, характерные для публицистического стиля (реальные истории, пагубное воздействие).
Интуитивное предположение об отнесенности коллокации к публицистическому стилю может быть проверено статистически на большом корпусе текстов. Обратимся к корпусам НКРЯ [6] и рассмотрим меру устойчивости и специфичность коллокатов реальные истории, пагубное воздействие, бурный восторг. Они устойчивы по критерию MI , причем меры их устойчивости близки (см. таблицы 1 и 2 ниже).
Таблица 1. – Расчет MI по газетному корпусу НКРЯ
| Коллокация | Статистики
по газетному корпусу НКРЯ (N=173518798) |
|||
| f(n) | f(c) | f(n,c) | MI | |
| Реальная история | 38934 | 71591 | 182 | 3.5 |
| Пагубное воздействие | 841 | 7439 | 40 | 10.12 |
| Бурный восторг | 6278 | 4677 | 41 | 7.92 |
Таблица 2. – Расчет MI по основному корпусу НКРЯ
| Коллокация | Статистики по основному корпусу НКРЯ (N=229968798) |
|||
| f(n) | f(c) | f(n,c) | MI | |
| Реальная история | 26297 | 89152 | 96 | 3.24 |
| Пагубное воздействие | 1167 | 10445 | 18 | 8.41 |
| Бурный восторг | 8270 | 15749 | 54 | 6.58 |
Обратимся к формуле расчета меры неслучайности языкового явления, предложенной в работе [7] и рассчитаем меру неслучайности S по формуле:
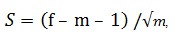
где f– частота коллокации в газетном корпусе НКРЯ, m– математическое ожидание частоты коллокации в газетном корпусе НКРЯ (с учетом того, что его доля составляет 0.43 от объема объединенного корпуса (основного и газетного); расчеты приведены в таблице 3.
Таблица 3. – Расчет меры неслучайности коллокации в газетном корпусе НКРЯ
| Коллокация | f(НКРЯ) | f(ГК) | f(НКРЯ)
+ f(ГК) |
m | S |
| Реальная история | 96 | 182 | 278 | 119.54 | 5.62 |
| Пагубное воздействие | 18 | 40 | 58 | 24.94 | 2.82 |
| Бурный восторг | 54 | 41 | 95 | 40.85 | -0.13 |
Неслучайной считается единица с мерой S выше 2. Как видим, коллокация бурный восторг не является специфической для газетного текста (ее относим к группе стандартных метафор). Коллокации реальная история и пагубное воздействие можно считать специфичными для газетного текста, причем коллокация реальные истории более специфична (что объяснимо: в журналистике есть жанр реальной истории (realstory)).
В исследуемых нами газетах встречается много коллокаций, относящихся к общественно-политической сфере: гражданин города, административный кодекс Беларуси, общественная жизни и др. Некоторые устойчивые сочетания отличаются особой возвышенностью: водоворот жизни, безжалостный мир и др. Часто присутствовали терминологические коллокации. Можно утверждать, что хотя гродненские студенты-журналисты чаще используют устойчивые словосочетания, присущие языку газеты вообще (реальная история, журналистская братия), иногда в их статьях присутствуют нетривиальные вариации таких, «общегазетных», устойчивых сочетаний (человек сегодня àhomo-sapiens сегодня).
Литература
1. Хохлова, М.В. Исследование сочетаемости и устойчивости лексических единиц автоматическими методами / М.В. Хохлова // Структурная и прикладная лингвистика. Выпуск 8. – СПб., 2010. – С. 206–218.
2. Боярский, К.К. Введение в компьютерную лингвистику: учеб. пособие / К.К. Боярский. – СПб: НИУ ИТМО, 2013. – 72 с.
3. Ягунова, Е.В. Слово – коллокация – синтаксические конструкции – текст. Единица анализа и контекст / Е.В. Ягунова //Автоматическая обработка текстов на естественном языке и компьютерная лингвистика : учеб. пособие / Е.И. Большакова [и др.]. – М.: МИЭМ, 2011. — 272 с. – С. 17–43.
4. Захаров, В.П. Статистический метод выявления коллокаций / В.П. Захаров, М.В. Хохлова // Языковая инженерия: в поиске смыслов / Доклады семинара «Лингвистические информационные технологии в Интернете»: XI Всероссийская объединённая конференция «Интернет и современное общество». Под ред. В.Ш. Рубашкина и В.П. Захарова. – СПб., 2008.
5. Станкевич, А.Ю. Связность сочетаний квазилексем: инструмент определения / А.Ю. Станкевич // Компьютерная лингвистика: научное направление и учебная дисциплина.– Гомель: ГГУ им. Ф. Скорины, 2010.– 236 с.– С. 162–166.
6. Национальный корпус русского языка [Электронный ресурс]. – Москва, 2003–2014. – Режим доступа: http://ruscorpora.ru/. – Дата доступа: 21.03.2015.
6. Национальный корпус русского языка [Электронный ресурс]. – Москва, 2003–2014. – Режим доступа: http://ruscorpora.ru/. – Дата доступа: 21.03.2015.
7. Шайкевич, А.Я., Савчук,С.О. Анализ лексико-семантических особенностей региональной прессы (на примере газет Гродненского региона Беларуси) [Электронный ресурс] / А.Я. Шайкевич, С.О. Савчук // Компьютерная лингвистика и интеллектуальные технологии.Вып. 13 (20). – Режим доступа: http://www.dialog-21.ru/ digests/dialog2014/ materials/ pdf/ ShaikevichAYSavchukSO.pdf– Дата доступа: 10.03.2015.